关于 gc 日志, 网上有丰富的资料, 另外周志明的《深入理解 Java 虚拟机: JVM 高级特性与最佳实践》一书, 在第二版中的第 3.5.8 小节也补充了关于 gc 日志的介绍;
但是真等拿到一个具体的 gc log, 才发现网上很多的内容都停留在一个比较初级的层次, 只是介绍了最基本的情况; 其对于生产环境中正在使用的 CMS, G1 收集器涉及很少, 对各种 gc 相关的 jvm 参数, 它们在 gc 日志中的具体作用, 也少见一个详细的整理; 另外, 对 gc 日志的管理运维, 我也很难看到一篇好文章来认真讨论;
基于以上状况, 我决定在这里写下这篇文章, 从我自己的角度去对 java gc 作一个全面的总结;
补充说明: 本文所述内容涉及的 jvm 版本是: Java HotSpot(TM) 64-Bit Server VM (25.60-b23) for linux-amd64 JRE (1.8.0_60-b27);
与 gc 相关的 jvm 选项
以下选项可以开启 gc 日志:
1 | # 打印 gc 的基本信息 |
-verbose:gc 与 -XX:+PrintGC 在功能上是一样的; 其区别在于 -verbose 是 jvm 的标准选项, 而 -XX 是 jvm 的非稳定选项; 另外, -XX:+PrintGCDetails 在启动脚本中可以自动开启 PrintGC 选项;
以下选项可以控制 gc 打印的内容:
1 | # 输出 gc 发生的时间, 形如: yyyy-MM-dd'T'HH:mm:ss.SSSZ +0800 |
gc 日志开头的元信息输出
一般在 jvm 启动时, gc.log 都会在开头打印出与当前 jvm 相关的一些元信息:
1 | # jvm 版本信息 |
在 jvm 选项中使用不同的收集器, 所输出的 gc 日志格式会有所不同, 尤其是 G1, CMS 等实现复杂的收集器; 不过, 在一些细节的区别之外, 大部分收集器在整体结构上都会维持一定的共性, 以方便使用者阅读;
gc 日志内容分析
我选取了几段有代表性的 gc 日志, 包括 ParNew, PS, CMS, G1, 其中相同或相似的内容我作了合并, 内容不同的部分则单独整理; 同时我也选取了一些有代表性的 gc 日志选项所打印的内容, 作重点介绍;
(1) 打印 gc 发生的时间点, 与 jvm 启动后经历的时间长度
对应的 jvm 选项是 PrintGCDateStamps 和 PrintGCTimeStamps; 其中, gc timestamp 是从 jvm 启动至日志打印当时所经历的秒数;
1 | # -XX:+PrintGCDateStamps |
(2) 打印 gc 发生的原因及类型
对应的 jvm 选项是 PrintGCCause; 当然, 在 jdk8 之后, 默认会打印 gc cause;
这里 G1 和其他的收集器在格式上稍有区别, 因为它的设计与其他收集器差异较大, gc 的条件及类型都不尽相同;
G1 收集器的格式, 第一个括号内是 gc 原因, 第二个括号内为 gc 类型:
1 | # -XX:+PrintGCCause |
其他收集器的格式, 括号内是 gc 原因, 括号之前是 gc 类型:
1 | # -XX:+PrintGCCause |
其中 gc 类型是这样界定的: 没有 STW 则为 GC, 若发生了 STW, 则为 Full GC;
(3) 打印 gc 发生时每一个岁数上对象存活量分布图
对应的 jvm 选项是 PrintTenuringDistribution, 这是一个十分有用的性能调参选项;
1 | # -XX:+PrintTenuringDistribution |
这里需要注意的是, 最后一列 “各 age 累积总大小”, 是将从 age 1 到当前 age 的所有 size 累积相加而成的; 它们驻留在 survivor 区中, 如果其累积 size 超过了 “Desired survivor size”, 将会有部分装不下 survivor 的对象晋升至年老代;
与此同时, 即便没有超过 “Desired survivor size”, 达到 “MaxTenuringThreshold” 的对象也将进入年老代; 为了避免数据频繁地从年轻代晋升至年老代, MaxTenuringThreshold 的合理值应该在 15 左右;
如果 survivor 区的 size 设置过小, 则每次达到 “Desired survivor size” 时的最大 age 都将远小于 15, 这同样会造成数据频繁地从年轻代晋升至年老代, 此时就需要考虑是否要调大 survivor 区的大小了;
(4) 打印 jvm 运行时间与 STW 的时间
对应的 jvm 选项是 PrintGCApplicationStoppedTime 和 PrintGCApplicationConcurrentTime;
当发生 “stop the world”, jvm 便会在 gc 日志里记录应用运行的时间:
1 | # -XX:+PrintGCApplicationConcurrentTime |
而当 gc 结束时, jvm 便会在 gc 日志中记录停顿的时间:
1 | # -XX:+PrintGCApplicationStoppedTime |
(5) 打印 jvm 进入 safepoint 的统计信息
对应的 jvm 选项是 PrintSafepointStatistics; 除了 gc pause 之外, 还有很多因素会导致 jvm STW 进入 safepoint, 例如: 反优化(deoptimize), 偏向锁生成(enable biased locking) 与偏向锁撤销(revoke bias), thread dump 等;
1 | # -XX:+PrintSafepointStatistics –XX:PrintSafepointStatisticsCount=1 |
其中:
第一列 vmop 是 vm operation, 本次 stw 要做的事情;
total 是 stw 发生时, jvm 的总线程数;
initially_running 是正在运行, 尚未进入 safepoint 的线程数, 对应后面的时间是 spin;
wait_to_block 是进入 safepoint 后尚未阻塞的线程数, 对应后面的时间是 block;
所以, sync = spin + block + cleanup;
最后一列 vmop 则是 jvm 进入 safepoint 实际动作所消耗的时间;
以上就是一些典型的与 gc 相关的 jvm 选项; 下面要说的是各典型的收集器日志;
(6) ParNew 收集器的日志
这种是最标准的 gc 日志格式, 也是各种资料上介绍得最多的内容, 日志的含义我已标注在注释上:
1 | # -XX:+PrintGCDetails |
(7) Paravel Scavenge 收集器的日志
PS 虽然也不是按照标准框架实现的收集器, 但是其 gc 日志与 ParNew 等相比几乎是一脉相承, 几无二致, 此处便不再赘述;
1 | # -XX:+PrintGCDetails |
(8) CMS 收集器的日志
CMS 的 gc 日志基本上是按照 CMS 收集算法的执行过程详细记录的;
1 | # -XX:+PrintGCDetails |
1 | # CMS-concurrent-mark-start |
1 | # CMS-final-remark |
关于 CMS 收集算法的流程逻辑, 请参见另一篇文章: CMS 收集算法学习与整理;
(9) G1 收集器的日志
1 | # -XX:+PrintGCDetails |
关于 CMS 收集算法的流程逻辑, 请参见另一篇文章: G1 收集算法学习与整理;
gc 日志文件的运维最佳实践
关于 gc 日志文件本身的管理运维, 也是存在一些经验的, 错误的运维方法将为性能排查甚至系统运行带来麻烦与阻碍;
(1) 避免新的 gc 日志覆盖旧的 gc 日志
使用 -Xloggc 可以指定 gc 日志的输出路径, 错误的经验会引导我们作如下设置:
1 | -Xloggc:${CATALINA_BASE}/logs/gc.log |
这种设置带来的问题是: 当系统重启后, 新的 gc 日志的路径与老的 gc 日志路径相同, 新日志便会将旧日志覆盖;
系统一般不会随便重启, 如果重启, 很可能是出现了故障, 或者性能问题; 在这种设置下, 如果重启前忘了备份当前的 gc 日志, 那重启后就没有性能诊断的依据了 (当然也可能事先使用 jstack, jmap 等工具作了部分现场的保留, 并非完全无法作诊断, 这里只是单从 gc 的角度讨论);
所以, 最佳的方法是为 gc 日志的命名带上时间戳:
1 | -Xloggc:${CATALINA_BASE}/logs/gc.log-$(date +%Y-%m-%d-%H-%M) |
这样只要不是在同一分钟内两次重启, gc 日志都不会被覆盖;
(2) gc 日志的 rolling 滚动
如果系统一直在健康运行, 那么 gc 日志的大小就会稳定地增长, 占用磁盘空间, 最后导致磁盘空间报警; 显然我们需要对 gc 日志作 rolling, 主流的方式是使用 jvm 自己的选项作控制:
1 | # 启用 gc 日志 rolling |
最后日志目录下的内容类似于下面这个样子:
1 | gc.log-2018-03-01-17-58.0 |
最后一个带 “.current” 后缀的就是当前正在写的 gc 日志;
但这种方式有个问题, 日志文件名没有规范 当达到最大文件数量后, jvm 会选择回头覆盖最老的那个日志文件, 并把 “.current” 后缀也挪过去, 这种模式对日志收集相当得不友好, 我们很难定位当前正在写入的 log 文件;
于是有另外一种思路想来解决 gc 日志收集的问题, 其采用了挪走并写空的方式:
1 | # 按天作 rolling |
这种方法看似可行, 但忽略了一个问题: cp 和 echo 写空这两步并非原子操作, 在这个处理过程中, jvm 依然在试图往日志里写内容, 这就造成了写空后的 gc.log 接不上被 rolling 的老日志了, 甚至在字节层面上都不是完整的编码了, 打开看一下就报了这种错:
1 | "gc.log" may be a binary file. See it anyway? |
即便是使用 strings 命令搜索文本内容, 也只能得到一些残缺的内容, 完全无法分析问题了;
说到底, gc 日志的收集陷入这样的困境, 其实是 jvm 自己的支持度不够好; 像 nginx, 使用 kill -USER1 便可以作到原子切割日志; logback 的 RollingFileAppender 也是自身提供了完整的支持; 可惜 jvm gc log 没有走类似的路线, 而是采用了一种古怪的类似于 rrd 的环状模式, 直接造成了收集日志的困难;
gc 日志的辅助分析工具
其实拿到一个冗长的 gc 日志文件, 对着枯燥的数字, 我们很难对 待诊断的系统建立起一个直观而感性的性能健康状态的认识;
这里有一个十分出色的 gc 日志可视化分析工具: gceasy, 其对于 gc 问题的诊断可谓是如虎添翼;
上传 gc 日志并分析诊断, gceasy 可以给出多维度的可视化分析报告, 以友好的交互自动诊断系统的问题所在:
- Heap Statistics (堆状态统计)
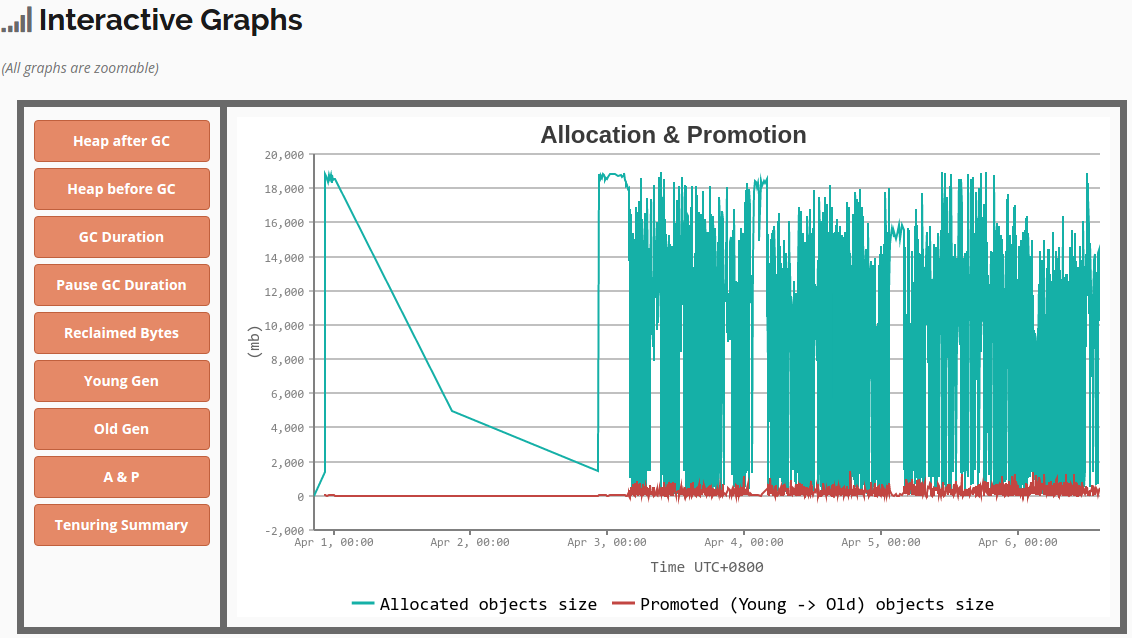 heap_statistics
heap_statistics - GC Phases Statistics (gc 算法流程各阶段的时间统计)
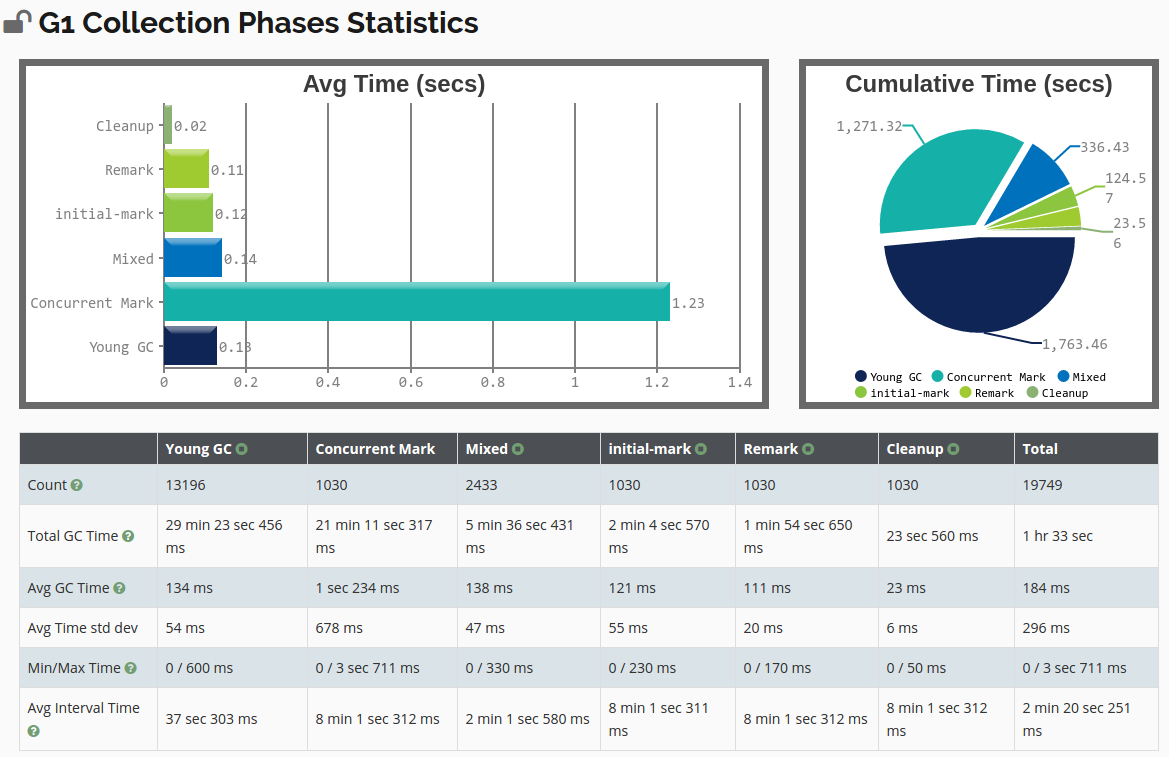 gc_phase_statistics
gc_phase_statistics - GC Time (gc 时间统计)
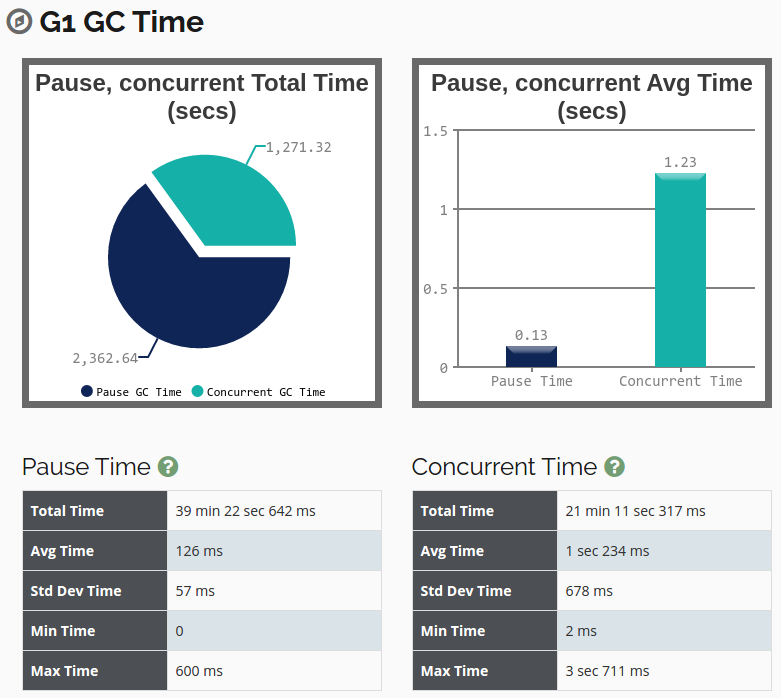 gc_time_statistics
gc_time_statistics - GC Cause (gc 原因分布统计)
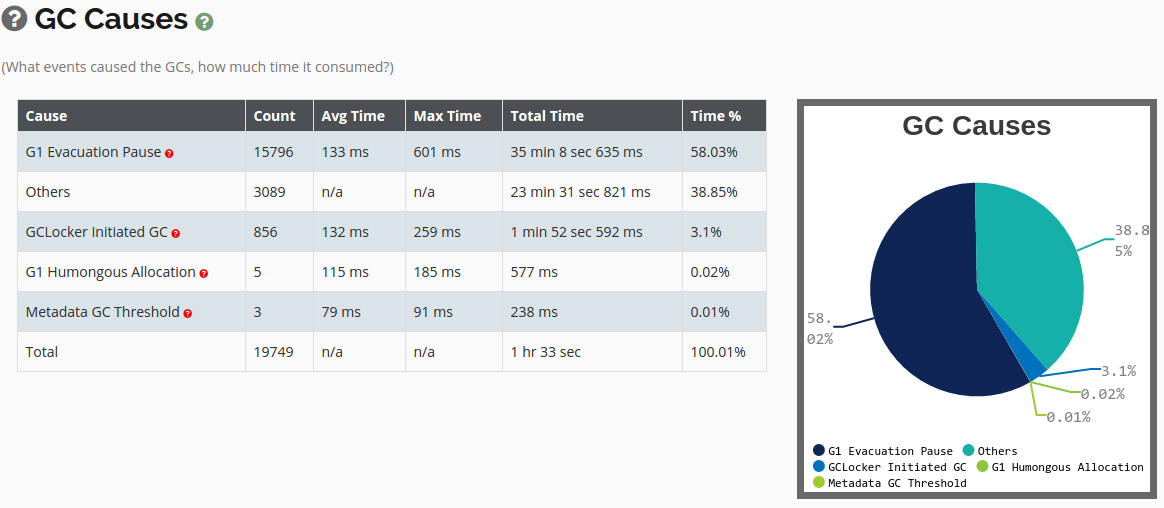 gc_cause_statistics
gc_cause_statistics - tenuring summary (survivor 区每一个岁数上存活对象 szie 统计)
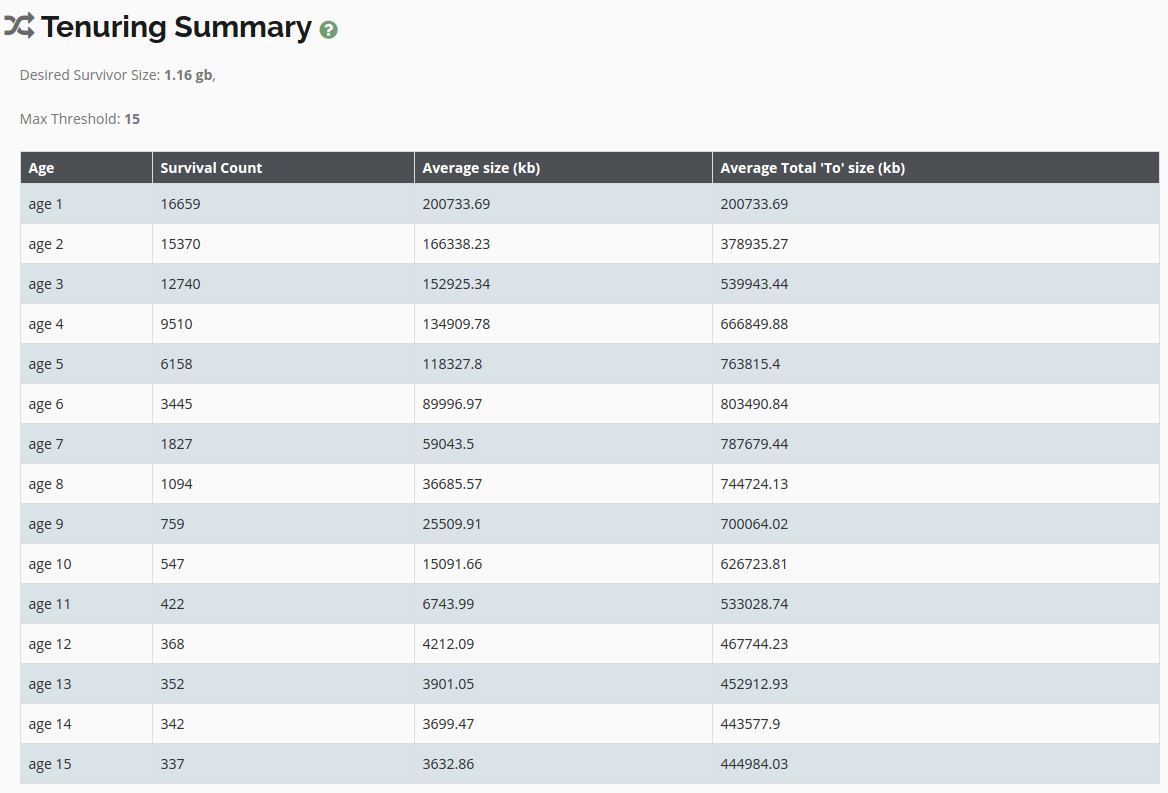 tenuring_summary
tenuring_summary
站内相关文章
参考链接
- 深入理解 Java 虚拟机: JVM 高级特性与最佳实践 (第2版) 3.5.8 理解 GC 日志
- Understanding G1 GC Logs
- Java -verbose:gc 命令
- jvm参数-verbose:gc和-XX:+PrintGC有区别? (阿里云)
- jvm参数-verbose:gc和-XX:+PrintGC有区别? (segmentfault)
- Some junk characters displaying at start of jboss gc log file
- GC日志中的 stop-the-world
- java GC进入safepoint的时间为什么会这么长
- ROTATING GC LOG FILES
- Forwarding JVM Garbage Collector Logs
- jvm-对象年龄(-XX:+PrintTenuringDistribution)

