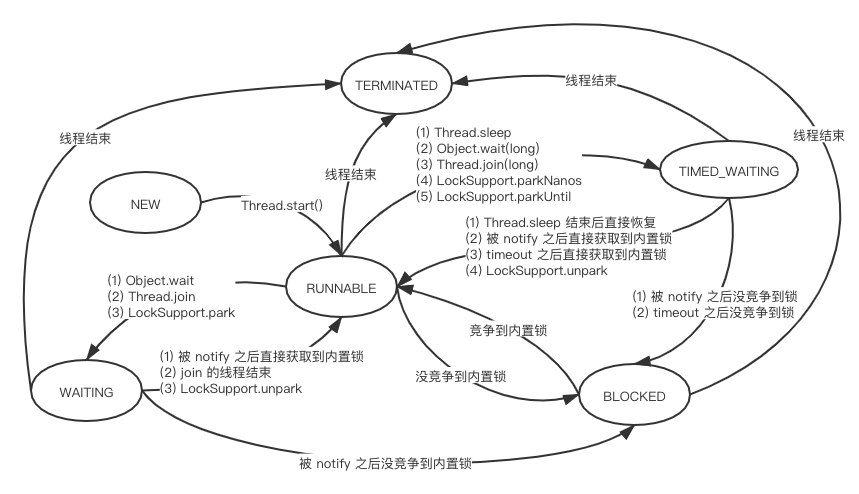
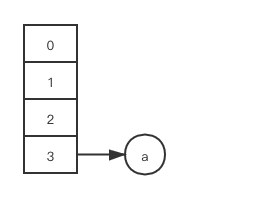
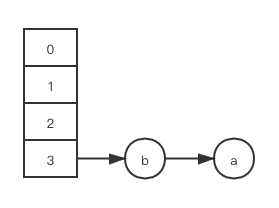
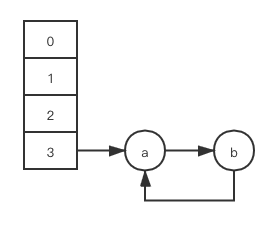
staticfinalinttableSizeFor(int cap){ int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
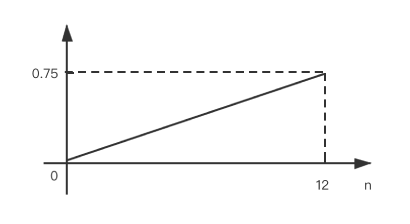
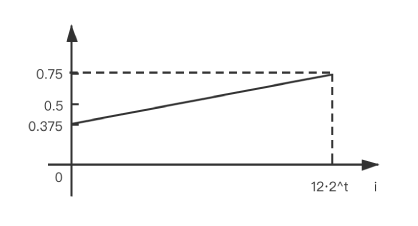
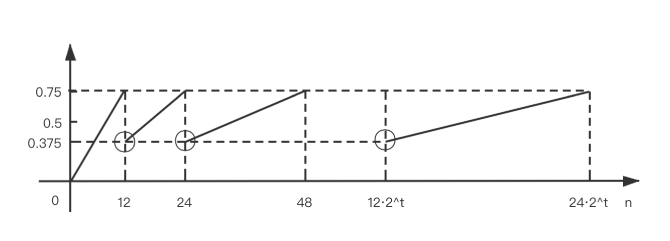
As a general rule, the default load factor (0.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost.
Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity.
0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
好在,生活中有一样东西在万物中最为珍贵:希望。希望是一种可能性,就算发生的概率再低,只要不是零,它就配得上叫做希望。墨菲定律说,只要事情存在可能性,那么给足了时间,就总有它发生的一天。我在这里写博客不正是这样的一件事吗?看起来似乎已没什么通达之径指向我的世界,可实际上这个网站一直在与互联网保持着连接!谁又敢说将来的某一天,一定不会有人误打误撞在浏览器里输入了我的博客地址,踏进我为 ta 打开的这扇门呢?
(WARN-31472 dbusstuff.c:197) Connection Error (/usr/bin/dbus-launch terminated abnormally with the following error: No protocol specified Autolaunch error: X11 initialization failed.
是的,我们每个人出生于全然不同的环境,自然而然得塑成了不同的生活习惯与兴趣爱好。我一直追求的是一种求同存异的关系,但是何谓同,何谓异?究竟该如何拿捏同与异的分寸,我之前并未深入细致得思考过,我内心一直持有的是这样的观点:态度,态度是关键。生活中有些事情是我们的心之所向,我们愿素履以往;有些事情虽谈不上喜欢,但却理解喜欢这些事的人,并认同追求这些事给 ta 带来的价值,或许在长期的交往过程中,我们也会在潜移默化之中同样爱上这些事情;还有些是我们不太理解,也不感兴趣的事情;当然必不可少的,总也会有些事,令我们十分反感,完全不能接受。
但这终究还是有区别的,学习与工作,校园与社会。我真心怀念学校图书馆里无忧无虑看书的日子,相比之下,在社会上,毕竟拿着公司发的工资,干活与完成任务才是第一要义。我喜欢计算机,但这和在互联网公司上班是两回事,很多人倾向于用工作的忙碌程度来评估自己的价值,把自己交给繁忙,得到了心里的踏实,但在 IT 行业,这是个死亡陷阱,是一个让人陷入原地踏步无法快速提升自己的重要原因。我不喜欢上班的感觉,可是哪有不上班的道理,不上班哪有经济来源?
# by curl sh -c "$(curl -fsSL https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)" # by wget sh -c "$(wget https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh -O -)"
这其实是个很扯淡的事情: mac 的按键体系与其他传统的笔记本不一致, 它多了一个 command 键, 更改了 delete 键的含义, 少了一些诸如 backspace, page up/down, home/end 等按键, 如此迥异以致很多传统的快捷键在 mac 下都有很大的不同, 有些功能需要依靠按键组合来实现, 让初次接触的人很不习惯; 另外 mac 的各个按键有着独特的图像标识, 在一些软件的快捷键设置面板上会频繁出现, 如果不稍作了解, 有很多标识是不太看得懂其象形含义的, 这里我对所有 MacBooK 基础按键的标识作一个整理:
按键标识
含义
⌘
Command
⇧
Shift
⌥
Option, Alt
⌃
Control
↩
Return/Enter
⌫
Delete
⌦
向前删除键 (Fn + Delete)
↑ / ↓ / ← / →
上下左右 箭头
⇞ / ⇟
Page Up/Down (Fn + ↑/↓)
Home / End
Fn + ←/→
⇥
右制表符 (Tab键)
⇤
左制表符 (Shift+Tab)
⎋
Escape (Esc)
使用总结
我相信从 Windows 迁移到 mac 环境是一件阻力不大的事情, 这也是大部分人的模式, 而且这部分人群的行业分布十分广泛, 软件工程师只是其中一个子集而已; 然而对于一个长期使用 linux PC 的程序员来说, 事情就没那么富有吸引力了: mac 所能给予的生产力与效率, linux 也不遑多让, 另外对于开源软件有信仰的人来说, 这事甚至没有任何商量的余地; 但其实我很清楚, 这本质上不过是一个人内心深处的偏见与执念, 长期使用 mac 的人, 让他们转投 linux 阵营也是不可能的事; 即便在 linux 业界之内, 关于 fedora, arch 与 ubuntu 的争论也是从未休止过; 关于 OS X 其实有大量的优点在本文中完全没有被提及, 可能是我觉得不值得花费时间去探索这些东西, 我在工作中所创造的价值完全依托于 linux 主机, 所以我亦使用 linux 作为我个人笔记本的操作系统, 借用这种方式以熟悉, 并更好得理解我的作品在生产环境下的工作原理: 兴许这就是我无可救药的执念…… 我听说阿里巴巴的办公笔记本发放的是 MacBook Pro 15’, 并且强烈不建议使用自己的笔记本办公, 非要使用的话必须安装各种安全监视与审计软件, 毕竟信息安全是上市公司的头等大事; 这么说无论如何, 我都得慢慢得去适应 mac 环境下的办公模式了, 否则将来因为强烈排斥使用公司统一发放的 MacBook Pro 而拒绝了某公司的 offer, 就有点扯淡了;
]]>
<blockquote>
<p>新东家发的办公笔记本是 MacBook Pro, 来之前我还觉得挺高大上, 然而真正开始用的时候发现, OS X 对于 linux 用户来说实在是太难于上手了, 甚至感觉比 Windows 系统还不习惯, Windows 好歹从前还是使用过的, OS X 简直就和初学者使用 vim 一样不知所措;</p>
</blockquote>
berkeley db 7.x 压力测试报告http://zshell.cc/2018/08/12/linux-other--berkeley_db7.x压力测试报告/2018-08-12T15:10:04.000Z2020-08-09T07:01:58.347Z
voidcreateMap(Thread t, T firstValue){ t.threadLocals = new ThreadLocalMap(this, firstValue); }
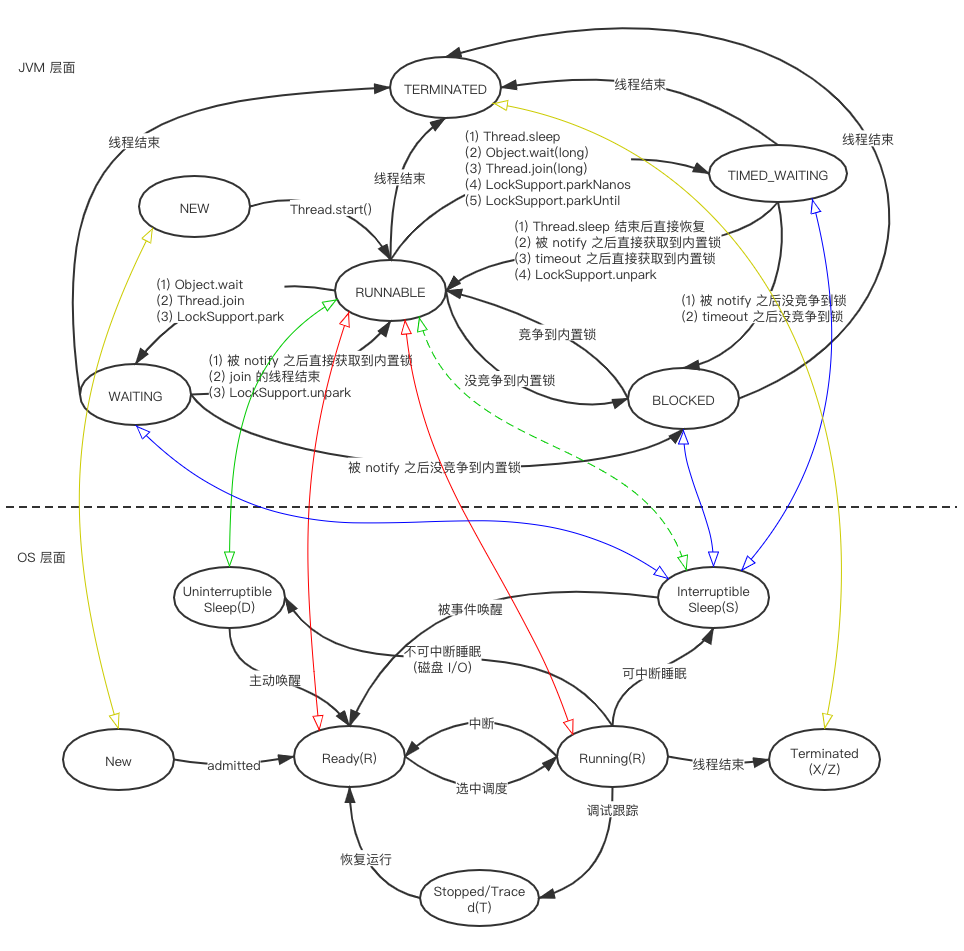
get 方法也是类似的道理, 从线程的 ThreadLocalMap 中获取以当前 ThreadLocal 为 key 对应的 value:
1 2 3 4 5 6 7 8 9 10 11 12 13
public T get(){ Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); }
staticclassEntryextendsWeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
privateintexpungeStaleEntry(int staleSlot){ Entry[] tab = table; int len = tab.length; // expunge entry at staleSlot tab[staleSlot].value = null; tab[staleSlot] = null; size--; // Rehash until we encounter null Entry e; int i; for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; tab[i] = null; size--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; // Unlike Knuth 6.4 Algorithm R, we must scan until null because multiple entries could have been stale. while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }
/* * InheritableThreadLocal values pertaining to this thread. This map is * maintained by the InheritableThreadLocal class. */ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
install_shadowsocks_go() { disable_selinux pre_install download_files config_shadowsocks if check_sys packageManager yum; then firewall_set fi install }
The authenticity of host '10.64.0.11 (10.64.0.11)' can't be established. RSA key fingerprint is SHA256:3O+bKYBXKHcYLBbltbuzu8dJbWaX42QHvkKeyABTyqU. RSA key fingerprint is MD5:ff:3f:57:5c:54:39:8c:71:50:71:aa:bf:1a:6e:a1:0f. Are you sure you want to continue connecting (yes/no)?
如果在 known_hosts 中存在该主机, 并且 ip 等信息并未发生变化, 则校验通过;
如果在 known_hosts 中存在该主机, 但是 ip 等信息发生了变化, 则会打印类似如下的 中间人攻击 告警信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-middle attack)! It is also possible that the RSA host key has just been changed. The fingerprint for the RSA key sent by the remote host is ad:12:0a:af:77:09:af:b0:65:16:9a:0a:04:57:2e:f1. Please contact your system administrator. Add correct host key in /home/zshell.zhang/.ssh/known_hosts to get rid of this message. Offending key in /home/zshell.zhang/.ssh/known_hosts:96 Password authentication is disabled to avoid man-in-the-middle attacks. Keyboard-interactive authentication is disabled to avoid man-in-the-middle attacks. Agent forwarding is disabled to avoid man-in-the-middle attacks. X11 forwarding is disabled to avoid man-in-the-middle attacks.
Host * # 对所有的 host 适用的配置 ForwardAgent no ForwardX11 no # 允许开启图形界面支持 RhostsAuthentication no RhostsRSAAuthentication no RSAAuthentication yes PasswordAuthentication yes FallBackToRsh no UseRsh no BatchMode no CheckHostIP yes StrictHostKeyChecking no # 默认的私钥文件, 按先后顺序依次获取 IdentityFile ~/.ssh/identity IdentityFile ~/.ssh/id_rsa Port 22 Cipher 3des EscapeChar ~