关于 elasticsearch, 吐槽最多的就是其前后版本的兼容性问题; 在任何一个上规模的系统体系里, 要将部署在生产环境中的 elasticsearch 提升一个 major 版本是一件非常有挑战性的事情; 为了迎接这一挑战, 作者所在部门专门抽调人力资源作前期调研, 故为此文以记之;
在这篇文章中, 我将从 client 端, 索引创建, query dsl, search api, plugins, 监控体系等多方面讨论了从 2.4.2 版本迁移到 6.2.2 版本的一系列可能遇到的兼容性问题及解决方案;
希望能给各位读者带来工作上的帮助!
万字长文, 高能预警! 如只希望了解最终结论, 请点击: #本文总结;
戊戌年春, 历时余月, 本文终于迎来了收尾;
这篇文章缘起于部门自建 elasticsearch 集群的一个线上故障, 这是我们技术 TL 在 elastic 论坛的提问: ES consume high cpu with threadlocal; 随着业务规模的扩大, 业务数据的积累, 我们意识到当前 2.4.2 版本的 elasticsearch 已经满足不了我们的需求, 此刻亟需升级我们的集群; 比较之后, 我们打算将 6.2.2 版本作为升级的目标, 并着手开始调研; 本文即是该升级调研的一个总结报告;
相比于公司内部发表的版本, 本篇博客对所有涉及公司内部的信息作了脱敏处理, 并在开篇第一节补充介绍了一下我们使用 elasticsearch 的方式, 以方便外部读者更好得理解本文的其余部分内容;
客户端兼容性问题
在这篇文章的编排结构中, 我将客户端兼容性问题摆在了第一的位置: 因为不管 rest api 如何变化, 或者如何不变, 都只能算是 “术”; 我们真正跑在生产环境中的系统, 使用的是 elasticsearch java client; client 端的基础兼容性问题才是根本之 “道”;
巨轮转向的前提: es-adapter
我相信, 搞过 elasticsearch major 版本升级的人都对 elastic 公司深有体会: 从不按牌理出牌, 一个毫不妥协的技术理想主义者, 在其世界里根本没有兼容性这个词; 对于这样的公司做出的产品, 升级必定是一个痛苦的过程;
如果请求 elasticsearch 的代码逻辑散落在部门众多业务线的众多系统里, 要推动他们修改代码势必比登天还难: 因为这个过程对他们的 PKI 没有任何帮助, 只会挤占他们的工时, 增加他们的额外负担和 “无效” 工作量, 他们一定不会积极配合, 我们将无法推动进展;
还好部门的 VP 有技术远见,在各系统建立之初, 就定下了访问 elasticsearch 的规范: 禁止各系统自己主动连接 elasticsearch, 必须统一由专门的系统代理, 负责语法校验, 行为规范, 请求监控, 以及统一的调优; 其余的系统必须通过调用其暴露出去的 dubbo 接口间接访问 elasticsearch; 这个系统被命名为 es-adapter;
当然, es-adapter 系统设计的早期也有一些硬伤, 并直接诱发了一个严重的线上故障: apache httpclient 初始化参数设置总结; 那次事故之后, 甚至有技术 TL 开始怀疑 es-adapter 成为了当前体系的瓶颈, 需要评估有无必要废弃该系统; 但是船大掉头难, 整改谈何容易? 最后还是老老实实完善了 es-adapter 的逻辑继续使用;
有的时候 es-adapter 也会做一些语法兼容性的逻辑, 比如之前从 1.7.3 升级到 2.4.2 的时候, 部分 dsl 语法的改动就完全在 es-adapter 上代理了, 对业务线无感知, 轻描淡写地升级了一个 major 版本; 尽管这么做带来了一些技术债务, 但确实为有限时间内的快速升级提供了可能性; 在后面的时间, 业务线可以慢慢地迭代版本, 逐渐适配新 elasticsearch 版本的 api, 偿还债务; 正所谓: 万事之先, 圆方门户; 虽覆能复, 不失其度;
不得不说, 当系统规模与复杂度发展到了一个 “船大难掉头” 的程度时, es-adapter 就像是《三体》中描述的 “水滴” 一样, 带领整个体系从一个更高的维度完成 “平滑” 转向; 没有 es-adapter, 升级 elasticsearch 到 6.2.2 就无从谈起; 只不过这次的情形相比上一次有些难看, 没法做到完全透明了, es-adapter 部分特有的逻辑设计在这次升级可能会栽一个跟头, 具体的内容请见下文: #search api 的兼容性;
升级过渡期 client 端的技术选型
关于 elasticsearch java 官方客户端, 除了 TransportClient 之外, 最近又新出了一个 HighLevelClient, 而且官方准备在接下来的一两个 major 版本中, 让 HighLevelClient 逐步取代 TransportClient, 官方原话是这样描述的:
We plan on deprecating the
TransportClientin Elasticsearch 7.0 and removing it completely in 8.0.
所以没有什么好对比的, 我们必须选择 HighLevelClient, 否则没两年 TransportClient 就要被淘汰了; 现在唯一需要考虑的是, 在升级过渡期, 怎么处理 es-adapter 中新 client 和旧 client的关系, 如何同时访问 6.2.2 与 2.4.2 两个集群;
值得注意的是, HighLevelClient 是基于 http 的 rest client, 这样一来, 在客户端方面, elasticsearch 将 java, python, php, javascript 等各种语言的底层接口就都统一起来了; 与此同时, 使用 rest api, 还可以屏蔽各版本之前的差异, 之前的 TransportClient 使用 serialized java object, 各版本之前的微小差异便会导致不兼容;
要使用 HighLevelClient, 其 maven 坐标需要引到如下三个包:
1 | <!-- elasticsearch core --> |
后两者没的说, 都是新引入的坐标; 但是第一个坐标, elasticsearch 的核心 package, 就无法避免与现在 es-adapter 引的 2.4.2 版本冲突了;
之前从 1.7.3 升 2.4.2 时, 由于 TransportClient 跨 major 版本不兼容, 导致 es-adapter 无法用同一个 TransportClient 访问两个集群, 只能苦苦寻找有没有 rest 的解决方案, 后来总算找到一个: Jest (github 地址: searchbox-io/Jest), 基本囊括了 elasticsearch 各种类别的请求功能;
但这还是架不住各业务线种种小众的需求(比如 nested_filter, function_score, aggregations 等等), 以致于对两个不同版本的集群, es-adapter 不能完美提供一致的功能;
这一次升 6.2.2, 又遇到了和上一次差不多的问题, 不过一个很大的不同是: 现在官方推荐的 HighLevelClient 是 rest client, 所以很有必要尝试验证下其向下兼容的能力;
我们经过 demo 快速测试验证, 初步得出了结论:
6.2.2 版本的 RestHighLevelClient 可以兼容 2.4.2 版本的 elasticsearch;
这也体现了 elasticsearch 官方要逐步放弃 TransportClient 并推荐 HighLevelClient 的原因: 基于 http 屏蔽底层差异, 最大限度地提升 client 端的兼容性; 后来我在其官方文档中也看到了相关的观点: Compatibility;
所以, 本次升级过渡期就不需要像上次 1.7.3 升 2.4.2 那么繁琐, 还要再引入一个第三方的 rest client; 现在唯一需要做的就是直接把 client 升级到 6.2.2, 使用 HighLevelClient 同时访问 2.4.2 和 6.2.2 两个版本;
HighLevelClient 的使用注意事项
(1) 初始化的重要选项
HighLevelClient 底层基于 org.apache.httpcomponents, 一提起这个老牌 http client, 就不得不提起与它相关的几个关键 settings:
CONNECTION_REQUEST_TIMEOUTCONNECT_TIMEOUTSOCKET_TIMEOUTMAX_CONN_TOTALMAX_CONN_PER_ROUTE
不过, HighLevelClient 关于这几个参数的设置有些绕人, 它是通过如下两个回调实现的:
1 | List<HttpHost> httpHosts = Lists.newArrayListWithExpectedSize(serverNum); |
(2) request timeout 的设置
对于 index, update, delete, bulk, query 这几个请求动作, HighLevelClient 与它们相关的 Request 类都提供了 timeout 设置, 都比较方便; 但是, 偏偏 get 与 multiGet 请求没有提供设置 timeout 的地方;
这就有点麻烦了, get 与 multiGet 是重要的请求动作, 绝对不能没有 timeout 机制: 之前遇到过的几次惨痛故障, 都无一例外强调了合理设置 timeout 的重要性;
那么, 这种就只能自己动手了, 还好 HighLevelClient 对每种请求动作都提供了 async 的 api, 我可以结合 CountDownLatch 的超时机制, 来实现间接的 timeout 控制;
首先需要定义一个 response 容器来盛装异步回调里拿到的 result:
1 | class ResponseWrapper<T> { |
下面是使用 CountDownLatch 实现 timeout 的 get 请求具体逻辑:
1 | /* get request with timeout */ |
(3) query 请求 dsl 的传参问题
es-adapter 之前查询相关的请求动作, 对业务线提供的接口是基于 search api 设计的, 就是下面这样的模型:
1 | { |
业务线需要提供以上参数给 es-adapter, 而这里面最重要的就是第一个 query 参数, 这里原先设计的是传一个 dsl 字符串; 但是现在我发现 HighLevelClient 的 SearchSourceBuilder 不能直接 set 一个字符串, 而必须是使用各种 QueryBuilder 去构造对应的 Query 对象;
这个问题就比较严重了, 如果要改就是牵涉到所有的业务线; 而且即便是想改, 也没那么简单: 这些 QueryBuilders 都没有实现 Serializable 接口, 根本没法被 dubbo 序列化;
权衡之下, 感觉还是要努力想办法把 dsl 字符串 set 进去; 我看到 SearchSourceBuilder 有一个方法是 fromXContent(XContentParser parser), 考虑到 dsl 字符串其实都是 json, 可以使用 JsonXContent 将 dsl 反序列化成各种 QueryBuilders; 摸索了一阵子, 验证了以下代码是可行的:
1 | String dslStr = "..."; |
(4) 无厘头的 adjust_pure_negative
整个 HighLevelClient 中, 最让人感到费解的一个东西就是一个神秘的属性:
1 | /* org.elasticsearch.index.query.BoolQueryBuilder */ |
先是看官方文档, 搜不到;
然后搜 google, 就找到这么一个稍微相关一点的帖子: What does “adjust_pure_negative” flag do?, 而其给出的唯一回复是 “You can ignore it“;
实在搜不到有效的信息, 我只好去扒源码; 然而, 除了如上所述的 BoolQueryBuilder 中的这坨, 再加上一些测试类, 就再也没在其他地方看到与 adjust_pure_negative 相关的逻辑了;
也许真的如 elastic 讨论组中所说的 You can ignore it? 但是现在有一个问题让我无法忽略它: 这个属性无法被 2.4.2 的 elasticsearch 识别, 但在 6.2.2 的 elasticsearch 中, 各个 QueryBuilder 的 toString() 方法会自动将其带上:
1 | { |
在上一节中提到, es-adapter 接受业务线传来的 query dsl str, 使用 6.2.2 的 elasticsearch 便会将上述语句传给 es-adapter; 如果其访问的索引已经迁移到 6.2.2 新集群, 那么该语句没问题; 但如果其访问的索引还未来得及迁移到新集群, es-adapter 会将该请求路由到旧的 2.4.2 集群, 接着便会发生语法解析异常;
这意味着, 在某个系统所需要访问的所有索引迁移到 6.2.2 新集群之前, 其 maven 依赖的 elasticsearch 版本, 不能提前升级到 6.2.2, 以阻止 adjust_pure_negative 的生成;
当然考虑到 major 版本升级所带来的语法规则的巨变已被 es-adapter 缓冲掉了绝大部分, 我相信各业务线也不希望把 elasticsearch 的 maven 版本给直接升上去的; 毕竟那意味着代码将红成一大片, 要花费大量的精力修改代码, 这等于把 es-adapter 原本要替其做的事, 提前自己给办了;
(5) 其他小众的需求
以上展示的是业务线普遍会遇到的情况, 然后还有两个比较小众的需求, 在个别系统中会使用到, 也是上面所提到的 nested_filter 和 aggregations;
关于 nested_filter 还稍顺利些, api 有一些变化但是新的 api 有新的解决方案:
1 | // 6.2.2 版本: 构造一个 携带 nested_filter 的 sort |
只不过这种顺利是建立在之前的不顺利基础上的: org.elasticsearch.search.sort.SortBuilders 没有实现 java.io.Serializable 接口, 各业务线的系统没法通过 dubbo 接口把参数传给我, 所以不得不自定义了上面的 NestedSort 类用于盛装 nested sort filter 的相关参数:
1 | public class NestedSort implements Serializable { |
好在 nested_filter 相关参数类别可以固化, 比较稳定, 自定义类也算是个解决方案了;
但是另一个小众需求就没那么省事了: aggregations; 之前 2.4.2 的 agg api 中, 有一个通用的方法:
1 | public SearchRequestBuilder setAggregations(byte[] aggregations) { |
elasticsearch 聚合的 api 比较丰富自由, 而上面方法中的 aggregations 参数是以字节的形式传过来的, 所以业务线可以自由发挥, 不受 es-adapter 的约束, 但可惜这个方法在 6.2.2 版本中取消了;
这样一来不得不回到束缚之中, 针对不同的聚合类型作各自的处理了; 可惜各个聚合类型依然没有实现 java.io.Serializable 接口, 所以还是得自定义类型去盛装参数了; 比如以下是针对分位数的聚合:
1 | public class PercentileAggregation implements Serializable { |
1 | PercentilesAggregationBuilder percentileAggBuilder = AggregationBuilders.percentiles(param.getPercentileAggregation().getAggName()) |
其他的聚合类型不再一一列举; 关于 aggregations 的 api 变化着实比较大, 好在使用它的系统比较少, 推动其修改逻辑阻力亦不是很大;
HighLevelClient 的使用基本上要解决的就是以上几个问题了; 解决了客户端的问题, 就是解决了 “道” 的问题, 剩下的 “术” 的问题, 都已不是主要矛盾了;
语法兼容性问题
语法兼容性问题便是上文所提及 “术” 的问题的主要表现形式; 这一节主要讨论三个方面: 索引创建的兼容性, query dsl 的兼容性, search api 的兼容性;
索引创建的兼容性
es 6.2 在索引创建方面, 有如下几点与 es 2.4 有区别:
首先是 settings 中的区别;
部分字段不能出现在索引创建语句中了, 只能由 elasticsearch 自动生成;
1 | "settings":{ |
这算是一个规范化, 这些字段原本就不该自己定义, 之前我们是复制的时候图省事, 懒得删掉, 现在不行了;
然后是 mappings 中的区别;
(1) 布尔类型的取值内容规范化
elasticsearch 索引定义的 settings/mappings 里有很多属性是布尔类型的开关; 在 6.x 之前的版本, elasticsearch 对布尔类型的取值内容限制很宽松: true, false, on, off, yes, no, 0, 1 都可以接受, 产生了一些混乱, 对初学者造成了困扰:
1 | // elasticsearch 2.4.2 |
从 6.x 版本开始, 所有的布尔类型的属性 elasticsearch 只接受两个值: true 或 false;
从当前 2.4.2 集群的使用状况来看, 这个改动对我们的影响不是特别大, 因为我们在定义索引创建 DSL 语句时, 很多布尔类型的选项都是用的默认值, 并未显式定义, 只有 index 属性可能会经常用到;
(2) _timestamp 字段被废弃
这个改变对我们的影响不是很大, 我们现在绝大部分索引都会自己定义 createTime / updateTime 字段, 用于记录该文档的创建 / 更新时间, 几乎不依赖系统自带的 _timestamp 字段;
况且, _timestamp 字段在 2.4.2 版本时, 就已经默认不自动创建了, 要想添加 _timestamp 字段, 必须这样定义:
1 | "_timestamp": { |
当然, 在 6.2.2 版本中, 以上定义就直接报 unsupported parameter 错误了;
(3) _all 字段被 deprecated, include_in_all 属性被废弃
在 elasticsearch 6.x, _all 字段被 deprecated 了, 与此同时, _all 字段的 enabled 属性默认值也由 true 改为了 false;
之前, 为了阻止 _all 字段生效, 我们都会不遗余力得在每个索引创建语句中加上如下内容:
1 | "_all": { |
从 6.0 版本开始, 这些语句就不需要再出现了, 出现了反而会导致 elasticsearch 打印 WARN 级别的日志, 告诉我们 _all 字段已经被 deprecated, 不要再对其作配置了;
与 _all 密切相关的属性是 include_in_all, 在 6.0 版本之前, 这个属性值默认也是 true; 不过不像 _all 的过渡那么温和, 从 6.0 开始, 我在 elasticsearch reference 官方文档里就找不到这个属性的介绍了, 直接被废弃; 而在其上一个版本 5.6 中, 我还能看到它, 也没有被 deprecated, 着实有些突然;
elasticsearch 放弃 _all 这个概念, 是希望让 query_string 时能够更加灵活, 其给出的替代者是 copy_to 属性:
1 | "properties": { |
这样, 把哪些字段 merge 到一起, merge 到哪个字段里, 都是可以自定义的, 而不用束缚在固定的 _all 字段里;
无论如何, _all 与 include_in_all 的废弃对我们来说影响都是很小的, 首先我们就很少有全文检索的场景, 其次我们也没有使用 query_string 查询 merged fields 的需求, 甚至将 _all 禁用已被列入了我们索引创建的规范之中;
(4) 史诗级大改变: string 类型被废弃
string 类型被废弃, 代替者是分词的 text 类型和不分词的 keyword 类型;
当前正在使用的 2.4.2 版本的集群里, string 类型大概是被使用最多的类型了; 保守估计, 一个普通的索引里, 60% 以上的字段类型都是 string; 现在 6.x 把这个类型废弃了, 就意味着几乎所有索引里的大多数字段都要修改;
不过好在, 这种修改也只是停留在 index 的 schema 映射层面, 对 store 于底层的 document 而言是完全透明的, 所有原始数据都不需要有任何修改;
经过搜索发现, 其实早在 elasticsearch 5.0 时, string 类型就已经被 deprecated 了, 然后在 6.1 时被彻底废弃, 详细的 changelog 见官方文档: Changelog;
仔细一想, 这个改变是有道理的: elasticsearch 想要结束掉目前混乱的概念定义;
比如说, 在 5.0 之前的版本, 一个字符串类型的字段, 是这样定义的:
1 | "xxx": { |
index 的原本含义是定义是否需要索引, 是一个布尔概念; 但由于字符串类型的特殊性, 索引的同时还需要再区分是否需要分词, 结果 index 属性被设计为允许设置成 not_analyzed, analyzed, no 这样的内容; 然后其他诸如数值类型, 亦被其拖累, index 属性的取值也需要在 not_analyzed, no 中作出选择; 不得不说这非常混乱;
要把这块逻辑理清楚, 第一个选择是再引入一个控制分词的开关 word_split, 只允许字符串类型使用, 第二种选择就是把字符串类型拆分成 text 和 keyword;
至于 elasticsearch 为何选择了第二种方案, 我猜主要还是默认值不好确定; 对初学者而言, 一般都习惯于使用默认值, 但是究竟默认要不要分词? 以 elasticsearch 的宗旨和初衷来看, 要分词, search every where; 但是以实际使用者的情况来看, 很多的场景下都不需要分词; 如果是把类型拆分, 那么就得在 text 和 keyword 中二选一, 不存在默认值, 使用者自然会去思考自己真正的需求;
现在逻辑理清楚了, index 的取值类型, 也就如上一节所说的, 必须要在 true 或 false 中选择, 非常清晰;
(5) mapping 中取消 multi types
从 elasticsearch 6.1 开始, 同一个 index(mapping) 下不允许创建多个 type, index 与 type 必须一一对应; 从下一个 major 版本开始, elasticsearch 将废弃 type 的概念, 详见官方文档: Removal of mapping types;
由于底层 Lucene 的限制, 同一个 index 下的不同 type 中的同名的字段, 其背后是共享的同一个 lucene segment; 这就意味着, 同一个 index 下不同 type 中的同名字段, 类型定义也必须相同; 原文如下:
In an Elasticsearch index, fields that have the same name in different mapping types are backed by the same Lucene field internally; In other words, both fields must have the same mapping (definition) in both types.
这个改变对我们是有些影响的, 我们有小一部分的索引都存在 multi types 的问题, 这就意味着需要新建索引来承接多出来的 type, 这些索引的使用者必须要修改代码, 使用新的索引名访问不同的 type;
query dsl 的兼容性
索引创建的兼容性调研只能算是一个热身, 按照以往经验, elasticsearch 一旦有 major 版本升级, query dsl 变动都不会小, 这次也不例外;
(1) filtered query 被废弃
其实早在 2.0 版本时, filtered query 就已经被 deprecated 了, 5.0 就彻底废弃了; 这的确是一个不太优雅的设计, 在本来就很复杂的 query dsl 中又增添了一个绕人的概念;
filtered query 原本的设计初衷是想在一个 query context 中引入一个 filter context 作前置过滤:
Exclude as many document as you can with a filter, then query just the documents that remain.
然而, filtered query 这样的命名方式, 让人怎么也联系不了上面的描述; 其实要实现上述功能, elasticsearch 有另一个更加清晰的语法: bool query, 详细的内容在接下来的第 (2) 小节介绍;
从目前 es-adapter 的使用情况来看, 依然有请求会使用到 filtered query; 好在 filtered 关键字一般出现在 dsl 的最外层, 比较固定, 这块可以在 es-adapter 中代理修改:
1 | { |
(2) filter context 被限定在 bool query 中使用
如下所示, 以下 dsl 是 elasticsearch 6.x 中能够使用 filter context 的唯一方式, 用于取代第 (1) 小节所说的 filtered query:
1 | { |
由于这个规范只是一个限定, 而不是废弃, 所以对目前生产环境肯定是没有影响, 只是需要各业务线慢慢将使用方式改成这种规范, 否则以后也会带来隐患;
(3) and/or/not query 被废弃
与 filtered query 不同, and query, or query, not query 这三个是语义清晰, 见名知意的 query dsl, 但是依然被 elasticsearch 废弃了, 所有 and, or, not 逻辑, 现在只能使用 bool query 去实现, 如第 (2) 小节所示;
可以发现, elasticsearch 以前为了语法的灵活丰富, 定义了各种各样的关键字; 要实现同一个语义的查询, 可以使用几种不同的 query dsl; 很多时候, 这样导致的结果, 就是让新人感到眼花缭乱, 打击了学习热情;
现在 and query, or query, not query 被废弃, 干掉了冗余的设计, 精简了 query dsl 的体系, 不得不说这是一件好事;
但从另一个角度讲, 每逢 major 版本升级就来一次大动作, 破坏了前后版本的兼容性, 让使用者很头疼; 想想 java 为了兼容性到现在都还不支持真正的泛型, 要是换 elastic 公司来操作, 估计 JDK 1.6 就准备放弃兼容了;
从 es-adapter 的使用情况来看, 目前业务线基本没有 and/or/not query 的使用, 相关逻辑大家都使用的 bool query, 所以这一点对我们影响有限;
(4) missing query 被废弃
要实现 missing 语义的 query, 现在必须统一使用 must_not exists:
1 | GET /_search |
这也算是对 query dsl 体系的精简化: 可以用 exists query 实现的功能, 就不再支持冗余的语法了;
这个改动对我们是有一定影响的, 目前不少的 query 都还在使用 missing;
另外, 由于从 missing 改为 must_not exists 结构变化大, 而且 missing 的使用比较灵活, 在 dsl 中出现的位置不固定, 这两个因素叠加, 导致在 es-adapter 中代理修改的难度非常高, 基本不可行;
所以, 关于 missing , 必须由业务线自己来修改相关代码了;
search api 的兼容性
相比于 query dsl 的巨大改变, search api 总体上延续了之前的设计, 仅有部分 search type 被废弃; 感觉上比较温和, 可惜却因为 es-adapter 一些没有前瞻性的设计而闪着了腰;
(1) search_type scan 被废弃
关于这一点, 我们早就作好了心理准备; 早在从 1.7.3 升 2.4.2 的时候, 我们就已经发现 scan 这种 search type 被 deprecated 了, 从 5.0 开始, 就要被彻底废弃了, 所以 es-adapter 同期开始支持真正的 scroll 请求 (可惜业务线使用得不多);
从类别上说, scan 只不过是 scroll 操作中的一种特例: 不作 sort, fetch 后不作 merge; 从执行效果上看, scan 相比 scroll 可能稍微快一些, 并会获得 shards_num * target_size 数量的结果集大小; 除此之外, 没有其他什么区别;
然而, 理论上很简单, 实际上却很棘手: 这源于 es-adapter 一个比较糟糕的设计:
1 | /* es-adapter 的查询服务 */ |
可以发现, 在当前的逻辑中, 业务线的 scan 请求, 是通过调用 query 方法并设置 search type 为 scan 来实现的; 这里的 scroll(param) 方法是个 private 方法; 当 es-adapter 升级 api 到 6.2.2 后, 就识别不了 scan 了;
这就要求 es-adapter 修改 scroll(param) 方法为 public, 然后各业务线直接调 scroll(param) 方法; 这需要一定的修改工作量;
(2) search_type count 被废弃
count 与 scan 一样早在 2.4.2 时就已经被 deprecated 了, 不过之前我们对 count 的关注度没有 scan 高; 在 2.4.2 版本 SearchType 类的源码注释中, elastic 官方是这么说明的:
1 | /** |
对于 es-adapter 来说, 修改方法很明显, 正如注释中所述: 该怎么请求就怎么请求, 拿到 response 后从里面取出 totalHits 就行了;
可惜, 如上一节所述, 同样由于 es-adapter 中糟糕的逻辑, 业务线需要通过调用 query 方法并设置 search type 为 count 来实现 count 请求; 现在没有 count 这个 search type 了, 需要业务线改成直接调用 count(param) 方法;
(3) search_type query_and_fetch 被 deprecated, dfs_query_and_fetch 被废弃
这两个 search type 被 deprecated 的时间比 scan 和 count 稍晚一些; 好在这两个 search type 比较冷门, 业务线知道的不多, 所以用的也不多; 后来只要发现有人这么用, 我们就会告诉他们这个 api 已经不推荐了;
所以, 相比 scan 和 count, query_and_fetch 和 dfs_query_and_fetch 被废弃的影响十分有限;
底层索引数据兼容性问题
根据官方文档, 6.x 版本可以兼容访问 5.x 创建的索引; 5.x 版本可以兼容 2.x 创建的索引;
背后其实是 lucene 版本的兼容性问题, 目前我们 2.4.2 版本的集群使用的 lucene 版本是 5.5.2, 而 6.2.2 版本的 elasticsearch 使用的 lucene 版本是 7.2.1;
由于主机资源有限, 没办法再弄出一组机器来搭建新集群, 我首先想到的是: 能否以 5.x 作跳板, 先原地升级到 5.x, 再从 5.x 升到 6.x;
但是看了官方文档, 这个想法是不可行的: Reindex before upgrading; elasticsearch 只认索引是在哪个版本的集群中创建的, 并不关心这个索引现在在哪个集群; 一个索引在 2.4.2 集群中创建, 现在运行在 5.x 版本的 elasticsearch 中, 这时候将 5.x 的集群升级到 6.x, 该索引是无法在 6.x 中访问的;其次我想到的是使用 hdfs snapshot / restore 插件来升级索引; 这种方式曾在之前 1.7.3 升级 2.4.2 版本时大量使用, 总体来说速度比普通的 scroll / index 全量同步要快很多; 但是看了官方文档, 发现这个想法也是不可行的, (文档链接: Snapshot And Restore):
A snapshot of an index created in 5.x can be restored to 6.x.
A snapshot of an index created in 2.x can be restored to 5.x.
A snapshot of an index created in 1.x can be restored to 2.x.接着我又想到了 elasticsearch 自带的 reindex 模块; reindex 模块也是官方文档推荐的从 5.x 升 6.x 时的索引升级方法; 经过 beta 测试, 我发现这个方法基本可行, 速度也尚可, 唯一需要注意的就是在 elasticsearch.yml 配置文件中要加上一段配置:
reindex.remote.whitelist: oldhost:port以允许连接远程主机作 reindex;
以下是 _reindex api 的使用方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17POST _reindex
{
"source": {
"remote": {
"host": "http://oldhost:9273"
},
"index": "source_idx",
"type": "source_type",
"query": {
"match_all": {}
}
},
"dest": {
"index": "dest_idx",
"type": "dest_type"
}
}除了 reindex 模块之外, 其实还有一种更保守的方法, 就是用基于 es-spark 的索引迁移工具来完成迁移, 这也是之前经常使用的工具;
工具兼容性问题
http 访问工具兼容性
目前我们经常使用的基于 http 的访问工具主要是 elasticsearch-head 和 cerebro;
关于 http 请求, elasticsearch 6.2.2 也有一个重大的改变: Strict Content-Type Checking for Elasticsearch REST Requests;
现在所有带 body 的请求都必须要加上 Content-Type 头, 否则会被拒绝; 我们目前正在使用的 elasticsearch-head:2 和 cerebro v0.6.1 肯定是不支持这点的, head 是所有针对数据的 CRUD 请求使用不了, cerebro 甚至连接机器都会失败;
目前, cerebro 在 github 上已经发布了最新支持 elasticsearch 6.x 的 docker 版本: yannart/docker-cerebro; 经过部署测试, 完全兼容 elasticsearch 6.2.2;
不过, elasticsearch-head 就没那么积极了, 目前最近的一次 commit 发生在半年之前, 那个时候 elasticsearch 的最新版本还是 v 5.5;
没有 elasticsearch-head 肯定是不行的, 这个时候就只能自己动手了;
首先, 肯定是希望从源码入手, 看能不能改一改, 毕竟只是加一个 Content-Type, 并不需要动大手术; 只可惜, 我 clone 下了 elasticsearch-head 的源码, 发现这个纯 javascript 的工程, 复杂度远远超出我的想象, 早已不是一个非前端工程师所能驾驭的了的; 我全局搜索了一些疑似 post 请求的逻辑, 但终究也没把握这些是不是真正要改的地方; 思来忖去, 只得作罢;
然后, 我开始思考能否通过间接的方式解决问题; 我注意到一个现象, 凡是带 body 的请求, body 必定是一个 json, 无论是 POST 还是 PUT; 那就是说, 如果必须要指定 Content-Type 的时候, 那就指定为 application/json 就 OK 了; 与此同时, 如果是一个不带 body 的 GET 请求, 携带上该 header 理论上也不会造成额外影响;
如果这个假设成立, 那我只需要对所有 elasticsearch-head 发起的请求挂一层代理, 全部转到 nginx 上去, 并统一加上个 header:
1 | server { |
测试环境下的实验验证了这个方案是完全可行的, 原本正常访问的请求以及原本不能正常访问的请求, 现在都没有任何问题了;
其实, 这个方案相比之前还是有自己的好处的: 它隐藏了真正的 elasticsearch 节点地址与端口号, 只对业务线暴露了一个代理 url, 从而更加灵活与可控;
插件兼容性
笼统上讲, cerebro 与 elasticsearch-head 也是插件, 只不过它们是独立部署的, 所以被划归到 http 访问工具的类别中了; 而这一小节要讲的, 则是真正的需要依赖于具体的 elasticsearch 节点的插件;
(1) elasticfence
这个插件追踪溯源的话是这个项目: elasticfence; 后来由于各种各样的需求, 我们在这个插件的基础之上, 作了大量的修改; 到目前为止, 跑在我们节点上的该插件代码已经与 github 上的原项目代码没有半毛钱关系了;
当前我们版本的 elasticfence 最大的功能是整合了 qconfig, 使得其拥有热配置及时生效的能力; 然而, 也正是这个功能, 成了该插件本次兼容 elasticsearch 6.x 的噩梦;
首先第一道困难是, 2.4 与 6.2 版本的插件 api 彻底大改变; 但这与接下来的困难相比, 也只不过是热个身而已;
当我把 pom.xml 中的 elasticsearch 版本从 2.4.2 改成 6.2.2 时, 意料之中地发现代码红了一片, 不过仔细一看, 发现 api 变化的尺度之大, 还是超出了我的预计: RestFilter 接口直接被干掉了;
1 | /** |
原本在 2.4.2 版本中, RestFilter 是该插件的核心组件, 所有的请求都经过该过滤器, 由其中的逻辑判断是否具有访问权限; 现在该类被干掉, 我又搜不到其他类似 filter 的代替者, 这就没法操作了;
经过一段时间的努力, 我终于在 google 和 github 的帮助下找到了解决该问题的线索, 6.2 版本其实是提供了一个类似的 api 的:
1 | // public interface ActionPlugin |
让插件的 main class 继承此接口, 使用 lambda 表达式十分简洁地解决问题:
1 | // public class ElasticfencePlugin extends Plugin implements ActionPlugin |
本以为搞定了 api 就万事大吉了, 然后就遇到了第二道困难: java security manager;
换句话说, 就是基于安全考虑, 默认情况下不允许插件往任何磁盘路径写入东西, 大部分磁盘路径的内容不允许读取, 不允许发起 http 请求或 socket 连接, 不允许使用反射或者 Unsafe 类; 还有其他无数的动作限制…… 要想使用, 就必须申请权限!
当前版本的 elasticfence 由于使用了 qconfig, 所以首先需要引入公司的 common 客户端以初始化标准 web 应用, 期间需要申请磁盘路径读写权限以及一些系统变量的读写权限; qconfig-client 本身也有定时任务发起 http 请求, 所以还需要申请 http 资源的请求权限;
然而实际上, 申请权限却不是那么顺利: 我按照官方文档 Help for plugin authors 的步骤申请了对应的权限, 重启节点, 发现无济于事: 该被禁止的依然被禁止; 我对 java security manager 的机制不熟悉, google 求助但所获甚少, 按正常的思路似乎遇到了阻碍;
根据官方的描述, 从 6.x 开始, security manager 已无法被 disable, 要想在当前版本里 run 起来, 安全机制就是绕不开的问题; 听起来似乎已经绝了, 遂内心生发出一个狠想法: 去改 elasticsearch 源码, 把 security manager 相关代码全部注释掉, 然后重新编译, 堂而皇之, 若无其事!
想了下我们确实没有代码行为方面的安全需求, 这个 security manager 对我们而言其实是可有可无, 现在它阻碍了其他对我们很有必要的东西, 那么它就是可无的;
不过 elasticsearch 可不是一般的 java 项目, 其体系之复杂, 依赖之错综, 让人望而生畏; 小心翼翼得 pull 下来最新的代码, checkout 到目标 tag v6.2.2, 然后傻了: gradle 下载不了任何依赖, 代码全是红色的一片;
在网上搜了一阵子, 按部就班地操作, 还算顺利, 总算在 Intellij IDEA 里将项目正常加载起来了; 不得不感叹, 关于 elasticsearch 6.x, 即便是本地 IDE 的环境问题, 也值得写一篇文章好好总结一下;
源码中与 java security manager 相关的代码主要有以下几个地方:
首先是 elasticsearch 的主方法( elasticsearch 启动后执行的第一个逻辑便是设置 security manager):
1 | // org.elasticsearch.bootstrap.Elasticsearch |
接着是 Bootstrap 类:
1 | // org.elasticsearch.bootstrap.Bootstrap |
最后是 BootstrapChecks 类:
1 | // org.elasticsearch.bootstrap.BootstrapChecks |
与 java security manager 相关的代码就在以上三个类中了; 可以发现它们都在 org.elasticsearch.bootstrap 包中;
重新编译后, 使用新处理过的 elasticsearch, 重启节点, 加载插件, 完美启动; 尽管这个问题暂时解决了, 但总是 “不太光彩”; 如果有人知道如何通过常规方法解决 security manager 的问题, 还请不吝赐教;
(2) elasticsearch-analysis-ik
这个插件没的说, 作为唯一一个在 elastic 公司任职的中国人, medcl 一定会在新版本发布第一时间更新 elasticsearch-analysis-ik, 与公司共进退;
安装了最新的 6.2.2 版本的 elasticsearch-analysis-ik, 重启节点, 加载插件, 完美运行;
(3) 其余插件
在 2.4.2 中, 还有两个使用到的插件, marvel 和 licence; 在 6.x 中, 这些插件已经被 x-pack 取代了, 下一节将会介绍, 此处不再赘述;
监控体系
基于 rest api + graphite + grafana 的方案
基于 elasticsearch 的 rest api, 我们可以使用脚本定时收集到集群内各种状态的指标; 使用 graphite 收集 elasticsearch 汇报的指标, 并以 grafana 作为前端展示; 使用以上开源框架自建的监控系统, 已经成为我们监控 elasticsearch 集群健康状况的主力工具 (这篇文章详细介绍了 elasticsearch 各种 rest api 收集到的指标以及将其可视化的方法: 使用 rest api 可视化监控 elasticsearch 集群);
将收集指标的脚本部署到 elasticsearch 6.x 测试节点, 发现 rest api 有了一些变化;
首先是 rest api 调用的参数的细微变化:
1 | # 2.4.2 的 _stats api 可以加一个不痛不痒的 all 参数 |
all 参数在 6.x 中已经不支持了, 不过这是个不痛不痒的参数, 加与不加对结果的输出似没有任何影响;
其余的 api 在调用的路径和参数上都没有什么变化, 比较顺利;
然后是调用 api 返回的内容有一些细微的变化:
1 | # 2.4.2 的 load 指标 |
6.2.2 的机器 load 指标收集, 随系统细分为了 1min, 5min 和 15min 三种, 也算是更精致了;
elastic 官方组件 x-pack
在 x-pack 诞生之前, elastic 官方提供了如下几个辅助工具: kibana, shield, marvel, watcher, 分别用于数据可视化, 权限控制, 性能监控和系统报警; 功能很强大, 可惜除了基础功能外, 进阶功能都要收费;
从 elasticsearch 5.0 开始, 这些独立的工具被 elastic 公司打成了一个包: x-pack, 同时在原有的基础之上, 又进一步提供了机器学习, 可视化性能诊断 (visual search profiler) 等其他特性, 并以 kibana 为呈现这些功能的载体; 只不过, 收费的功能还是一个都没少:
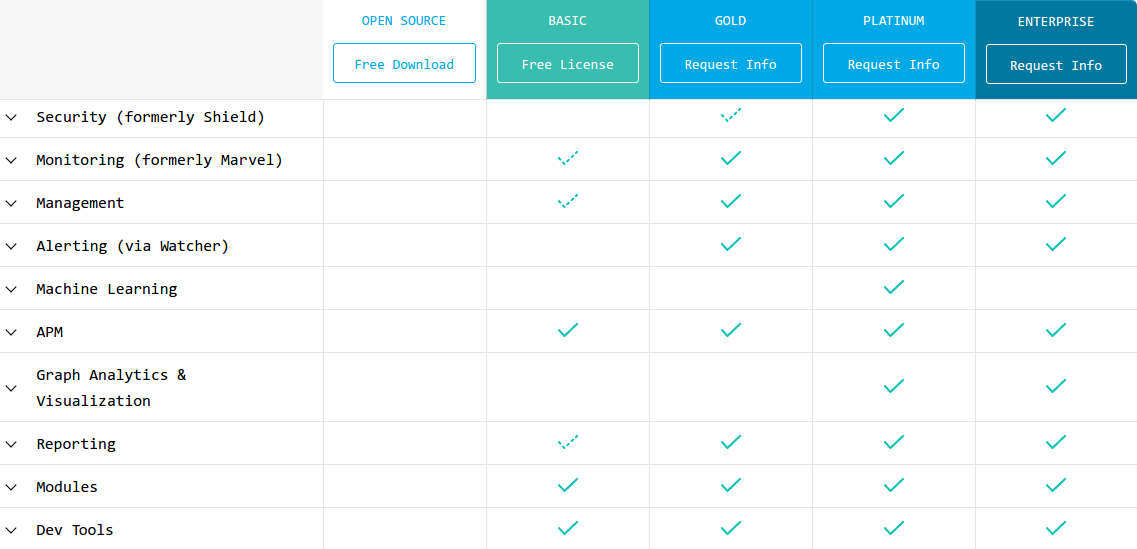
对我们来说, 之前我们主要使用到的是 marvel, 用于观察索引分片转移的源目节点与复制进度 (shard activity), 偶尔也会用于辅助自建的监控系统, 观察一些请求的 qps 和 latency;
我分别在 elasticsearch node 与 kibana 上安装了 x-pack 套件, 剔除了需要付费的 security, watcher, ml, graph 模块;
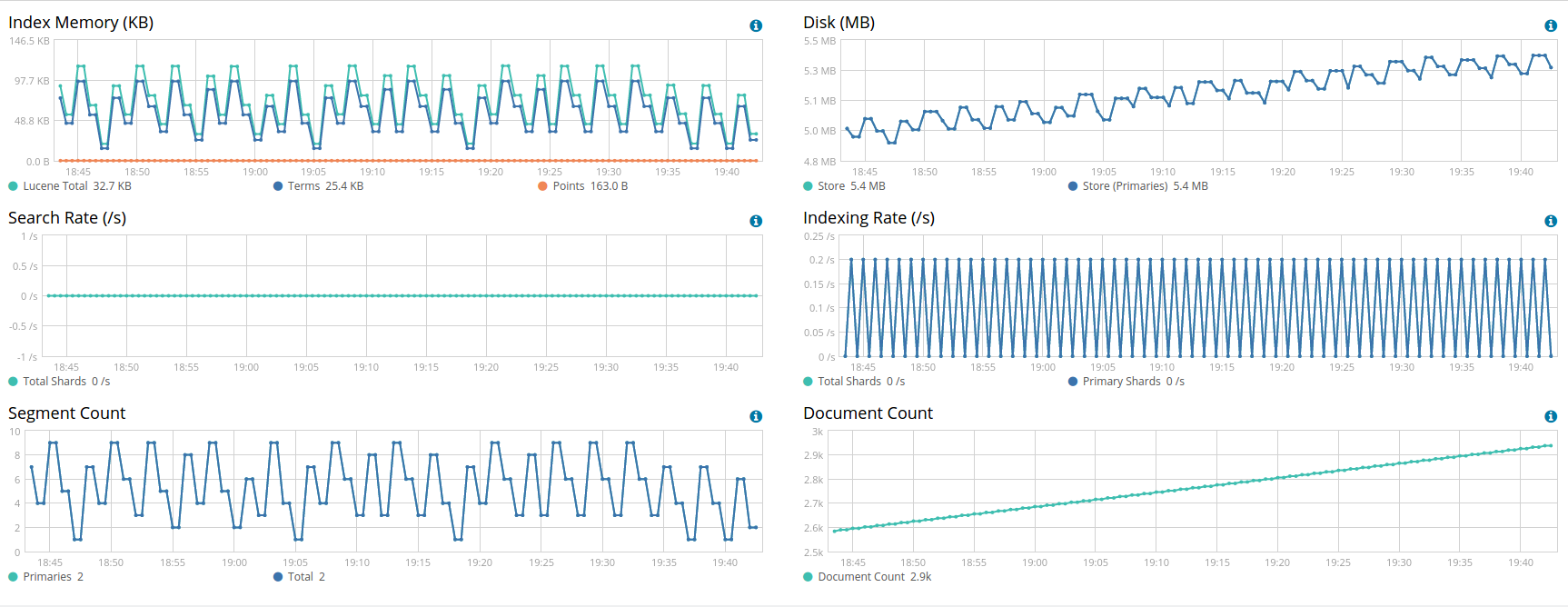
可以看到, monitoring 部分相比以前的 marvel, 总体结构上没有太大变化:
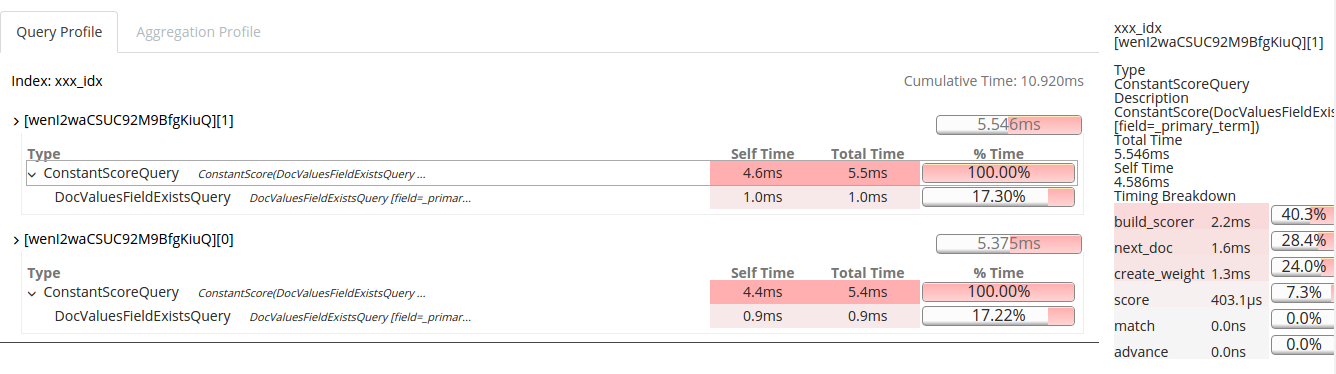
另外, 在 x-pack 免费的功能里, 还有一个比较实用的工具: dev-tools; 这里面有两个子栏目: search profiler 和 grok debugger; 其中, search profiler 在之前的 search api 基础上实现了可视化的诊断, 相比之前在 response json 字符串里面分析查询性能瓶颈, 这样的工具带来了巨大的直观性:
除了以上免费功能, kibana 本身还有最基础的 Discover 和 Visualize 数据可视化功能, 只不过各业务线都习惯于使用 head 工具来访问线上数据, 并且 kibana 的该部分功能较之以前无显著变化, 此处便不再详述;
以上便是 elasticsearch 6.x 下 x-pack 最常见的使用情况;
本文总结
本文主要讨论当前生产环境下从 elasticsearch 2.4.2 升级到 6.2.2 的可行性与兼容性问题;
首先是客户端兼容性问题:
elastic 公司新推出的 RestHighLevelClient 从 http 层面最大限度得屏蔽了各版本间的差异, 使得跨版本调用成为了可能; 使用 6.2.2 的 RestHighLevelClient 可以正常访问 2.4.2 的集群, 这为集群升级带来了便利; 对各业务线而言, 只有有限的 (诸如 aggregations) api 被迫需要修改, 其余的都可以延续下去;
其次是语法兼容性问题:
此处仍需细分为三个方面: create index, query dsl 和 search api ;
create index 方面, 其他的零碎变化都显得不痛不痒, 对我们的影响微乎其微, 唯一一个显著的大改变就是废弃了 string 类型, 改而细分出两个司职更明确的类型: text 与 keyword, 分别对应于分词和不分词的情形; 这个大改变需要我们对现有所有的索引作一次大整改;
query dsl 方面, 对我们的影响也在控制范围之内: 只有 missing 语句被废弃需要业务线作一定的修改, 其他的大多可以由 es-adapter 代理兼容;
search api 方面, 可能影响就比较大了: scan 和 count 两种 search type 被废弃, 并在 es-adapter 糟糕的设计之下, 影响被放大, 需要麻烦各业务线配合修改;
然后是索引数据迁移兼容性问题:
经过多方测试, 发现只有两种方法可以在我们这种跨两个 major 版本的情况下迁移索引数据: reindex 模块和 es-spark 工具; 好在这两种方法 (由其是后者) 之前就是我们主要的索引迁移工具;
接着是工具兼容性问题:
经过不断探索与变通, 最后 cerebro, elasticsearch-head, elasticfence, elasticsearch-analysis-ik, curator 等一系列原有生产环境下的 elasticsearch 工具 (插件) 都 “顺利” 实现了对 6.2.2 版本的兼容;
这其中, elasticfence 实现兼容的过程比较坎坷, 甚至还重新编译了 elasticsearch 的源码才解决了 security manager 的问题; 如果以后能通过常规方式解决安全的问题, 一定还得弄回去;
最后是监控体系兼容性问题:
得益于 6.x 版本 rest api 对先前的延续 (除了极个别 api 有细微调整之外), 之前生产环境使用的基于一系列开源方案的自建监控系统, 在 6.x 下依然做到了正常运转;
另外, 从 5.0 开始横空出世的 x-pack, 也在本次调研中被部署测试; 其中 monitoring, search-profiler 等功能都展示出了其实用的价值;
以上便是本文的全部内容;
站内相关文章
参考链接
- Changelog
- Removal of mapping types
- Strict Content-Type Checking for Elasticsearch REST Requests
- Compatibility
- State of the official Elasticsearch Java clients
- Elasticsearch 6 新特性与重要变更解读
- Help for plugin authors
- Intellij Idea 编译 Elasticsearch 源码
- elasticsearch: Building from Source
- Sequence IDs: Coming Soon to an Elasticsearch Cluster Near You
- Kibana+X-Pack
- Subscriptions that Go to Work for You

