nagios 的优点在于其插件拓展式的设计, 不过 nagios 给 ops 映像最深刻的, 是其出离复杂的配置文件; nagios 真的可以说是把配置文件当数据库使了;
作为备忘, 本文主要梳理 nagios 配置文件中的各种角色的关系与交互流程, 并就日常工作的经验总结一些 nagios 配置文件的部署及运维实践;
nagios 中的角色梳理
nagios 的配置文件角色众多, 各角色之间存在依赖关系, 从这个角度上看, nagios 很像是一个 “关系型数据库”;
针对我日常工作中遇到的情景, 其中可能涉及到的角色如下:
- service, 最核心的角色, 标识一个完整的检测服务单元;
- command, 报警检测命令;
- contact / contactgroup, 联系人 / 联系组, 当指标异常时的联系对象;
- host / hostgroup, 主机, 主机组, 报警检测的目标机器;
- timeperiod, 报警时间段;
nagios 各角色之间的关系
既然 nagios 的配置文件像一个关系型数据库, 那么一定可以作出它的 实体关系 ER 图, 绘制如下:
这是第一类简单的 ER 图, 其中 service 直接关联到单一联系人或单一主机; 除了这种情况外, service 也可以直接关联到联系人组或主机组, 再由组间接关联到具体的人或主机, 如下图所示: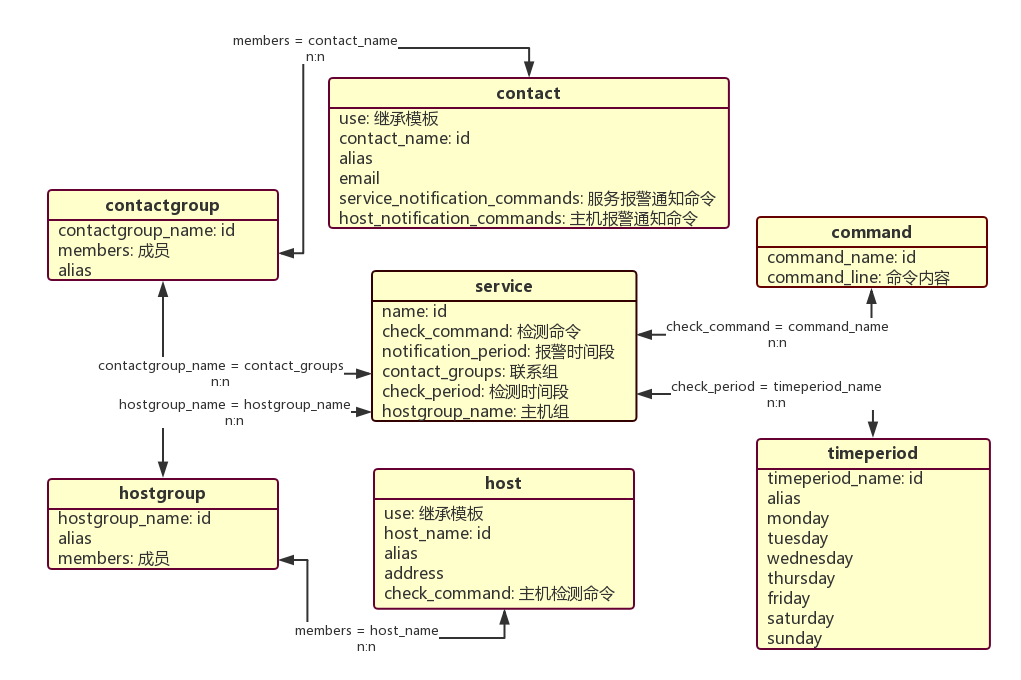
nagios command 的参数传递
由上面展示的两张图可以发现, service 是所有角色的中心, command 则是在整个流程中穿针引线的关键要素; 除了 service 中的 check_command 之外, host 也存在自己检测主机的 check_command, contact 则需要定义触发报警通知的 service_notification_commands 和 host_notification_commands; 所以说, command 的实现与调用十分关键, 而 command 调用的关键又在于其参数传递;
nagios 的参数分为两种类型, 一种是其自己的保留参数(宏定义), 常用的列举如下:1
2
3
4
5
6
7
8
9
10
11HOSTNAME # 主机名, 对应 host 角色中的 host_name 域
HOSTADDRESS # 主机地址, 对应 host 角色中的 address 域
NOTIFICATIONTYPE # 通知类型, 主要有 PROBLEM, RECOVERY 等
SERVICESTATE # 服务状态, 主要有 warning, unknown, critical, recovery 等
CONTACTNAME # 联系人, 对应 contact 角色中的 contact_name 域
CONTACTEMAIL # 联系人的邮件, 对应 contact 角色中的 email 域
SERVICEDESC # 服务的描述, 对应 service 角色中的 service_description 域
SERVICEOUTPUT # 服务的详细输出
这类宏定义, 在使用时会直接从角色配置项的具体域中直接获取值, 前提条件是配置项对应的域要已经配置了该值;
第二种类型是自定义类型, 在使用时是以顺序获取的, 如:1
2
3
4define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$
}
以上 check_ping 命令一共接受了 3 个参数: $HOSTADDRESS$, $ARG1$, $ARG2$, 除了 $HOSTADDRESS$ 是由 host 中的 address 域获得的, 其余两个自定义参数则按顺序填充至最终的命令中; 而调用该命令的服务配置如下:1
2
3
4define service {
...
check_command check_ping!50,10%!100,20%
}
可以看到, 分别将各个自定义参数按顺序放在命令的后面, 以 ! 隔开, 即为调用方式, 而对于 $HOSTADDRESS$ 这种宏定义参数, 则不需要主动设置, nagios 自己会带上它;
nagios 配置文件部署与运维实践
面对 nagios 这种不太友好, 略显复杂的配置, 想完全依托它实现自动化运维确实有些麻烦, 所以在不断的使用经验总结中, 我们渐渐形成了一套自己的使用方式; 另外, 我们还逐步将一些关键逻辑从 nagios 转移到自己开发的旁路系统中, 简化 nagios 的配置内容, 从而突出它的核心功能;
三类报警检测类型
首先从实现方式上分类, 我们使用了两大类: 使用插件拓展方式的 check_nrpe 和直接在 nagios server 上执行的本地检测命令;
(1) check_nrpe 对我们来说主要是用于非网络型的机器指标检测, 包括 check_load, check_disk, check_procs, check_swap, check_users, 以及戴尔供应商的硬件检测工具 (仅适用于实体机) check_openmanage, check_dell_temperature 等;
这类检测只能在 agent 上执行, 并且对于不同的主机环境, 其报警阈值各不相同, 需在 agent 上个性化定制; 所以, 这类指标检测只适用于 check_nrpe 的方式;
以下是一个典型的 nrpe 配置文件:1
2
3
4
5command[check_zombie_procs]=/home/nrpe/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/home/nrpe/libexec/check_procs -w 150 -c 200
command[check_disk]=/home/nrpe/libexec/check_disk -w 15% -c 10% -A -l
command[check_swap]=/home/nrpe/libexec/check_swap -w 90% -c 80%
command[check_load]=/home/nrpe/libexec/check_load -w 12,3.2,8 -c 12,3.6,8
另外除了以上通用的 nrpe 检查项之外, 对于一个标准的生产环境, 还可以定制特定的进程检查项:1
2
3
4
5command[check_crond]=/home/nrpe/libexec/check_procs -C crond -c 1:1
command[check_collectd]=/home/nrpe/libexec/check_procs -C collectd -c 1:1
command[check_ntpd]=/home/nrpe/libexec/check_procs -C ntpd -c 1:1
command[check_dnsmasq]=/home/nrpe/libexec/check_dnsmasq.pl -s 127.0.0.1 -H xxx.com -w 250 -c 300
command[check_flume-ng]=/home/nrpe/libexec/check_procs -a /home/apache-flume-ng/bin/flume-ng-manage -c 1:1
当然这些都是对辅助系统的检测, 对于生产环境下真正提供业务服务的系统, 则使用其他更灵活的方法监控;
(2) 直接在 nagios server 上执行的检测命令, 主要是网络型的机器指标检测, 如 check_ping, check_tcp, check_udp 等, 以及第三方的业务指标检测命令 check_graphite;
网络型的检测命令自不必多说, 其本身并不依赖于 agent 机器, 在 nagios server 上执行即可; 而第三方的业务指标检测命令 check_graphite, 主要依赖于 graphite_api 提供的接口获取业务指标, 亦不需要依赖 agent 机器;
以下为 check_graphite 命令的两种典型举例, 一正一反:1
2
3
4
5
6
7
8define command {
command_name check_graphite
command_line /usr/lib64/nagios/plugins/check_graphite --host 10.64.0.49:8888 --metric $ARG1$ --critical $ARG2$ --warning $ARG3$ --name $ARG4$ --duration $ARG5$ --function $ARG6$ 2>&1
}
define command {
command_name check_graphite_invert
command_line /usr/lib64/nagios/plugins/check_graphite --invert --host 10.64.0.49:8888 --metric $ARG1$ --critical $ARG2$ --warning $ARG3$ --name $ARG4$ --duration $ARG5$ --function $ARG6$ 2>&1
}
典型的 service 调用如下:1
2
3
4
5
6
7
8define service {
service_description xxxx
use service_template
...
check_period name_1_2_3_4_5_6_7_00:00-23:59
contact_groups common-contact
check_command check_graphite!'metrics.name.sample'!48!48!'query_time_too_long'!15!'max'
}
这里就要提到第一个被我们转移到旁路系统的功能: service 配置文件的自动生成;
在 应用中心的角色定位与功能总结 这篇文章里曾提及, 我们将设置报警项的过程留给业务线同学在应用中心的界面上完成; 对于新增的报警项, 我们写了一个 service-generator 系统, 按 appcode 划分, 定时将其刷到 nagios 的不同配置文件中;
我们使用 gitlab 管理 nagios 的配置文件, 其配置文件所在 base 路径已经关联到远程仓库; 与此同时, 在 nagios 实例所在主机上我们部署了 config-reload-manager 管理工具: 对于 service-generator 新增的配置内容, config-reload-manager 定时 reload nagios 进程, 如果成功加载, 则将本次新增内容 commit, 如果加载失败, 则单独 checkout 一个临时分支记录问题并报警, 重新 reset 到之前最新的版本, 恢复服务;
其实上述逻辑涉及到一个比较共性的问题: 系统动态配置文件的运维经验总结, 详细内容可以参考这篇文章;
(3) 第三类检测类型严格上说仍然属于直接在 nagios server 上执行的检测命令, 不过将其单独提出来是因为它的特殊功能: 服务状态检测; 在第一类 check_nrpe 检测中曾提到, 对于生产环境下的服务, 使用其他更灵活的方式监控, 这里指的就是基于端口的服务状态检测, 说的再直白一些就是使用 check_tcp / check_udp 命令检测服务端口的状态, 如果服务挂了, 对应的端口就会被探测到 connection refused 或者 timeout;1
2
3
4
5
6
7
8define service {
service_description alive_appcode_xxx_8080
use service_template
host_name l-xxx1.yyy.cn2,l-xxx2.yyy.cn2,l-xxx3.yyy.cn2,l-xxx4.yyy.cn2
...
contact_groups common-contact
check_command check_tcp!8080
}
这类检测依然要依赖应用中心: 在 应用中心的角色定位与功能总结 这篇文章里曾提及, 通过应用的标准化接入流程, 服务发布或启动的时候需要上报本次启动的相关信息给应用中心, 其中包括了服务所在主机地址及端口号; 每当有新服务注册, 我们会通过类似 service-generator 的方式生成对应的检测配置项;
淡化 contacts, 报警通知逻辑外置
对于一个报警系统而言, 最核心的功能就是检测异常; 除此之外, nagios 还可以通过 contact 配置通知到负责人, 然而这并不是报警系统的核心; 这里就要提到第二个被我们转移到旁路系统的功能: 报警通知逻辑;
一个公司有那么多工程师, 如果完全依靠 nagios 来实现通知, 就得把每个人的信息都配到文件里, 同时还要维护他们的群组关系, 按照 appcode 分类, 这无疑会增加 nagios 的配置量, 为运维带来复杂性; 况且, 通知逻辑并非 nagios 的核心功能, 权衡之下, 我们选择淡化 nagios 的 contact / contactgroup 元素, 让所有 service 的联系人都使用一个泛化的 common-contact, 而这个 common-contact 的通知命令, 会根据报警的内容, 自动选择合适的负责人;1
2
3
4
5
6
7
8
9
10
11define contactgroup {
contactgroup_name common-contact
...
service_notification_commands alert-notify
host_notification_commands alert-notify
}
define command {
command_name alert-notify
command_line /usr/bin/python /etc/nagios/objects/xxx/alert_notify.py "$NOTIFICATIONTYPE$" "$HOSTNAME$" "$HOSTALIAS$" "$HOSTADDRESS$" "$HOSTSTATE$" "$HOSTOUTPUT$" "$SERVICEDESC$" "$SERVICESTATE$" "$LONGDATETIME$" "$SERVICEOUTPUT$" "$CONTACTEMAIL$" "$CONTACTALIAS$" "$CONTACTNAME$" >> /var/log/nagios/alert.log.$(date +%F-%H) 2>&1
}
在 alert-notify 脚本中, 会根据报警内容查询应用中心, 选择合适的报警联系人, 合适的报警方式, 通知到位; 如果是 nagios 发送通知, 就只有配置的固定一组人会收到报警, 而改成这种外部的方式, 就具有了相当的灵活性, 甚至我们可以根据报警处理的进度反馈择机作报警升级处理, 比如:
(1) 报警方式从微信变成短信, 再变成电话语音报警;
(2) 报警联系人按照应用树组织架构, 从直接负责人, 逐步升级到 项目TL, 部门主管, 技术总监, VP, CEO 等;

